Vymezení, popis i klasifikace města a venkova jsou nedílnou součástí humánní geografie, ke kterému každý autor přistupuje jiným způsobem. Existuje velké množství ruzných přístupů jak tyto oblasti vymezit, některé uzpůsobené konkrétním specifickým rysům členění států, pro které jsou pak tyto přístupy platné, jiné zaměřené a používané globálně nebo pro uskupení více státu. Tyto přístupy se liší použitou prostorovou jednotkou i indikátory, pomocí kterých jsou oblasti členěny. V praxi jsou typologie s přesným vymezením venkovských a městských oblastí důležité pro vhodné zacílení různých rozvojových dotačních programů a rozdělení státní podpory.
Tato diplomová práce se v první části zabývá vytvořením datové sady s rozlišením na LAU2 za Evropskou Unii a přidružené státy. Základem datové sady jsou data statistického úřadu Evropské unie (Eurostat) o počtu obyvatel. Další indikátory jsou získány z volně dostupných datových zdrojů. Druhá část práce je zaměřena na vytvoření typologie městských a venkovských oblastí na základě vytvořené datové sady, platné pro celou oblast v detailu jednotek LAU2.
Cíle
Cílem diplomové práce je obohatit data administrativních jednotek Eurostatu nomenklatury NUTS o informace pocházející z volně dostupných zdrojů geografických dat a následně nad těmito daty provést vybrané socioekonomické (prostorové) analýzy. V první části práce bude vytvořena ucelená prostorová datová sada, ve které budou k administrativním jednotkám NUTS se zaměřením na LAU2 pomocí GIS operací přidány dodatečné informace do atributové tabulky tak, aby mohla být tato kompaktní datová sada využita pro druhou část práce. V druhé části práce budou provedeny vybrané socioekonomické analýzy, primárně zaměřené na problematiku a typologii venkovských/městských oblastí. Geografický rozsah práce je vymezen vstupní poskytnutou vrstvou (státy, které Eurostatu poskytly data o počtu obyvatel na úrovni LAU2).
Metody
Pro obohacení datové sady a agregaci výsledků do vyšších prostorových jednotek byly využity základní GIS operace jako intersect, join, summarize, atp. Funkce a využití těchto nástrojů jsou popsány například v oficiální dokumentaci Esri produktů (ArcGIS Desktop, 2020). Následně byla data analyzována pomocí různých statistických metod jako korelace a boxplot. Pro sestrojení příkazů v prostředí RStudio bylo čerpáno z oficiální dokumentace jazyka R (R Documentation, 2020) a v případě potřeby z programátorského fóra Stack Overflow (Stack Overflow, 2020). Výstupy těchto statistických metod mimo jiné posloužily jako podklad pro Analýzu hlavních komponent (PCA), kterou se zabývá např. Šarmanová (2012) a Meloun, Militký (2002) a jež využil pro analýzu prostorových dat také Pászto (2015) či Marek (2015). Jedná se o transformační metodu, při níž jsou původní vstupní proměnné transformovány do menšího počtu nových, skrytých proměnných, kterých je méně a mají vhodnější vlastnosti. Výsledky PCA byly shlukovány, pomocí algoritmu CLARA (Clustering Large Applications), který je modifikací algoritmu PAM (Partition Around Medoids) určenou pro rozsáhlé datové soubory. Výhodou algoritmu CLARA je to, že není citlivý na odlehlé hodnoty (outliery). Kromě statistických metod byly využity také zobrazovací metody nevyžadující statistické zpracování dat, pro které byly vytvářeny mapové výstupy, které byly dále vizuálně interpretovány (Horák, 2008). Mapové výstupy byly tvořeny v souladu s metodami tematické kartografie dle Voženílek, Kaňok a kol. (2011).
Výsledky
V této kapitole budou shrnuty výsledky a výstupy práce. Hlavními výstupy práce jsou vrstva LAU2 obahující nové atributy, hodnoty použitých hlavních komponent a informaci o zařazení do shluku jednotlivých oblastí, dále vrstva NUTS2 agregující výsledky PCA a shlukování do třech atributů s plošným podílem ploch městských, venkovských a venkovských zemědělských. Pro jejich prezentaci byla ve finální části práce vytvořena webová mapová aplikace.
První a časově velmi náročná část práce byla zaměřena na obohacení původní datové sady o další atributy. K tomuto účelu byla zvolena data CORINE Land Cover a OSM. Vytvoření této datové sady bylo nutné pro další analýzy, zaměřené na problematiku typologie městských/venkovských oblastí. Výsledná datová sada této části práce (přehled viz tabulka 2 v kapitole 6) obsahuje pět nových atributů z CORINE Land Cover, dvacetpět nových atributů z OSM a přepočet všech atributů na plochu.
Přehled atributů:
číslo
atribut
číslo
atribut
1
počet obyvatel
17
délka silnic 2. třídy
2
urbanizované území
18
délka silnic 3. třídy
3
zemědělské plochy
19
délka rychlostních silnic
4
lesy a polopřírodní oblasti
20
délka pěších zón
5
humidní území
21
délka rezidenčních silnic
6
vodní plochy
22
počet městských POI
7
polocha budov
23
počet POI typu ubytování
8
počet POI
24
počet POI typu kulturní zařízení
9
délka železnic
25
počet POI typu stravování
10
délka chodníků
26
počet POI typu zdravotní zařízení
11
počet kostelů
27
počet POI typu nákupní centra
12
délka tramvajových linek
28
počet POI typů banky a bankomaty
13
délka vodních toků
29
počet POI typu policie
14
délka cyklostezek
30
počet POI typu obchody
15
délka dálnic
31
počet POI typu univerzity
16
délka silnic 1. třídy
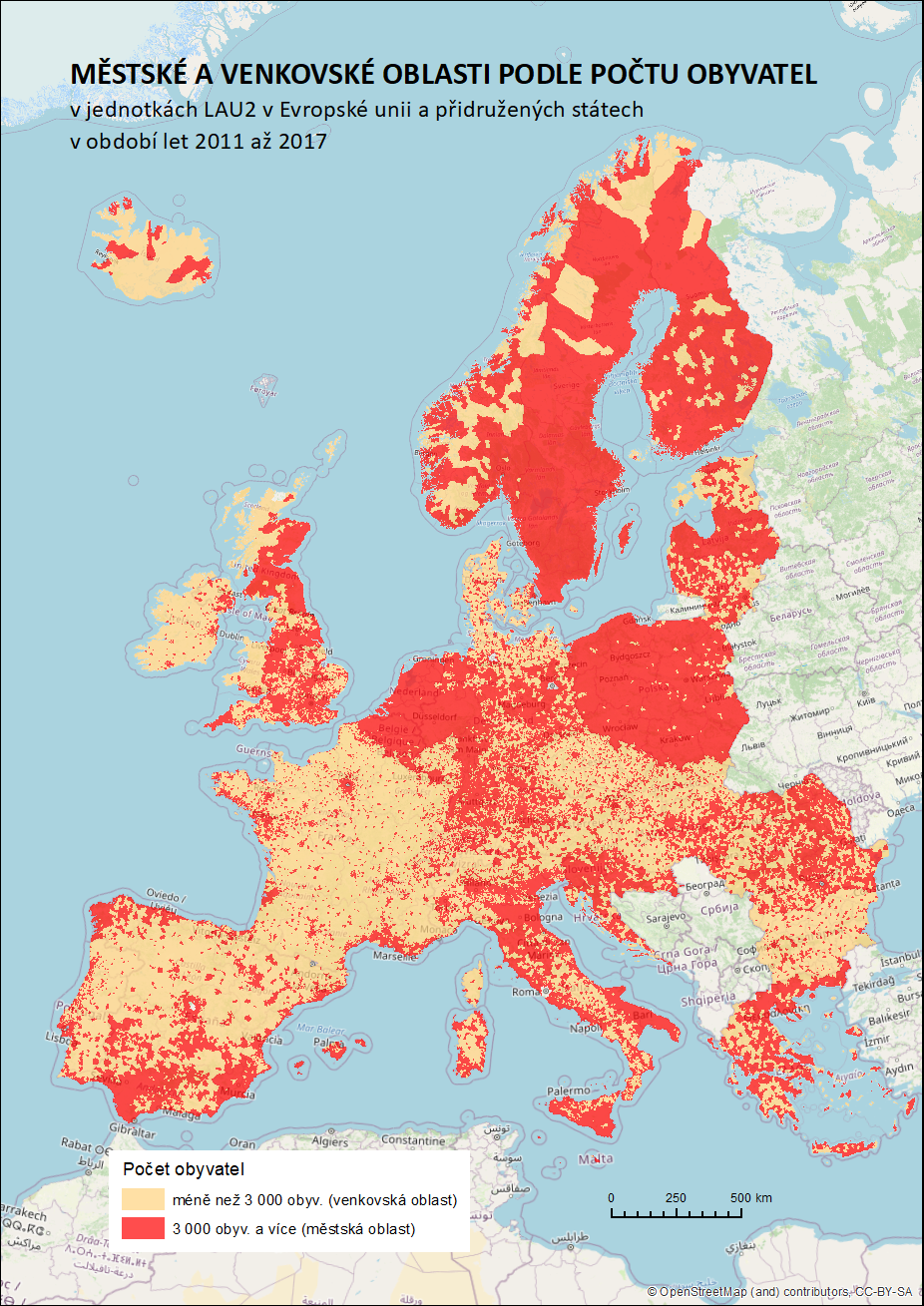
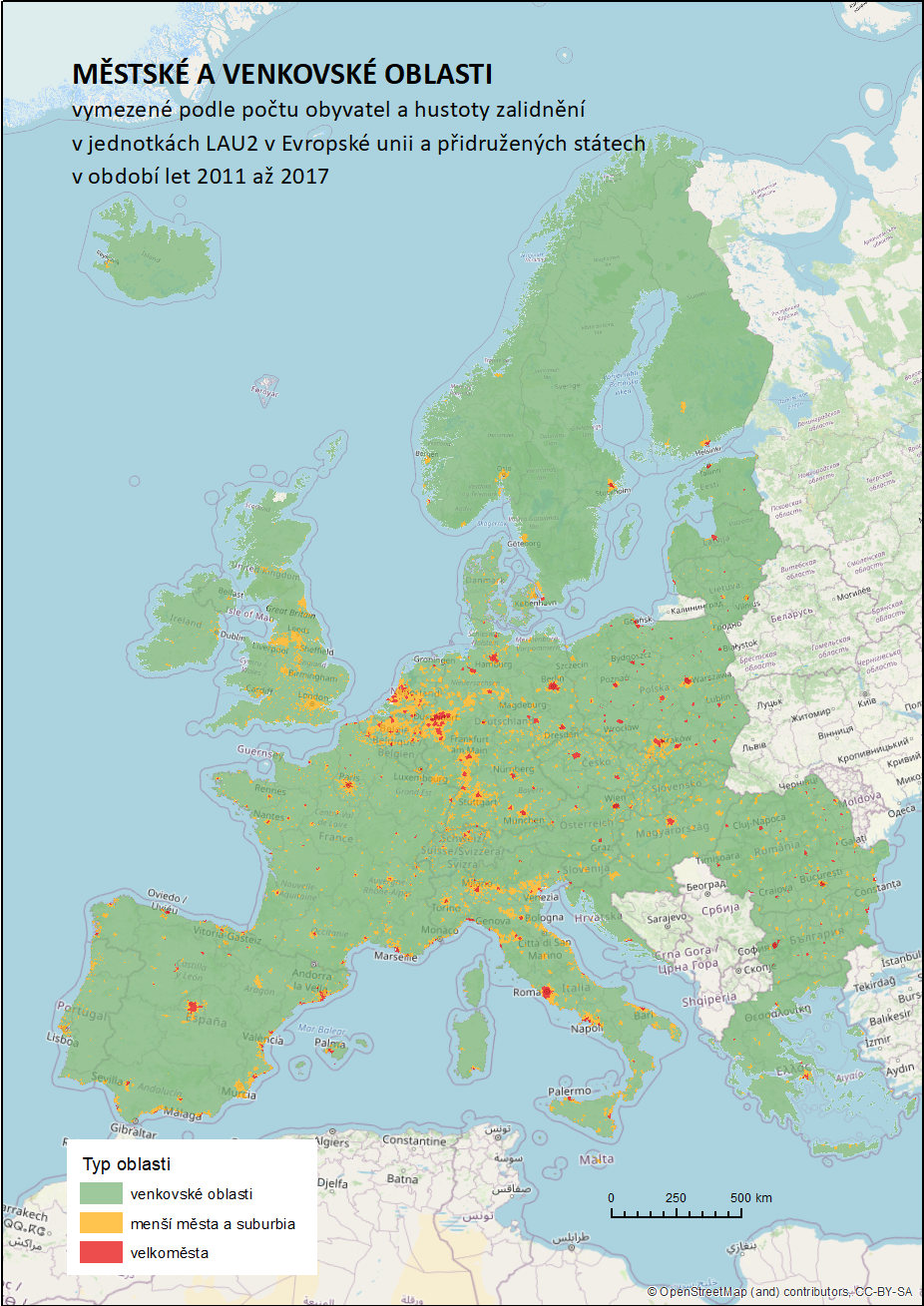
V další části práce byly vytvořeny tři základní klasifikace městských a venkovských oblastí založené na počtu obyvatel, hustotě zalidnění a jejich kombinaci, tedy bez použití nově vytvořených atributů. Jako hraniční hodnoty pro odlišení města a venkova byly zvoleny hodnoty vycházející z již existujících klasifikací či dokumentů. Vzhledem ke specifickým rysům administrativního členění jednotlivých států napříč celým zkoumaným územím však nejsou dostatečně přesné a použitím jedné univerzální hodnoty pro celé území jsou zkresleny.
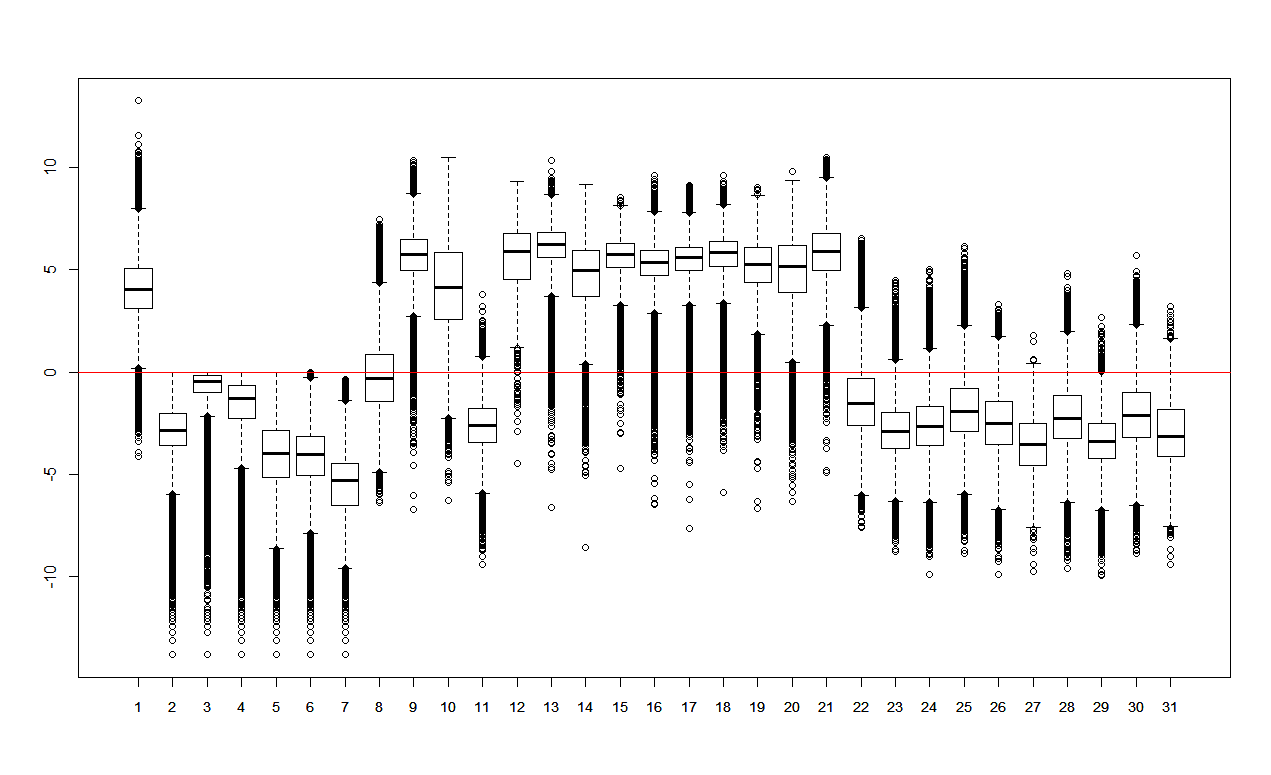
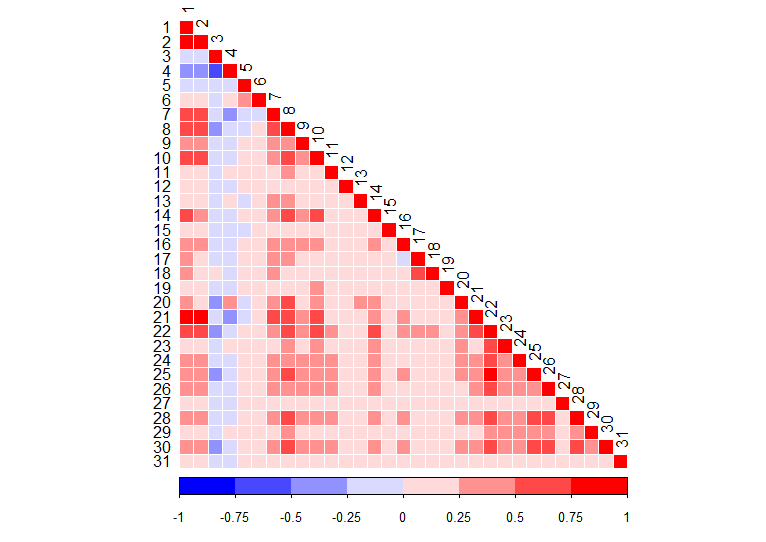
Před vytvořením nové typologie městských/venkovských oblastí (s použitím nových atributů) byla data analyzována pomocí boxplotů a korelačních matic. Pomocí boxplotů bylo určeno, že se v atributech jak přepočítaných tak i nepřepočítaných na plochu vyskytují outliery. Z tohoto důvodu byl zvolen Spearmanův korelační koeficient pro ohodnocení korelací před samotnou analýzou hlavních komponent. Rovněž byla provedena i analýza hlavních komponent se všemi atributy přepočítanými na plochu, na základě které bylo rozhodnuto redukovat počet atributů. Odebrány byly atributy s příliš velkým výskytem nulových hodnot, atributy málo relevantní vzhledem ke smyslu analýzy a naopak přidán byl atribut počtu obyvatel (přehled použitých atributů viz tabulka 3). Aby byl zajištěn vznik hlavní komponenty vhodné pro odlišení městských a venkovských oblastí byla zachována korelující skupina atributů vhodných k tomuto účelu.
Boxplot hodnot přepočtených na plochu
Korelace hodnot přepočtených na plochu
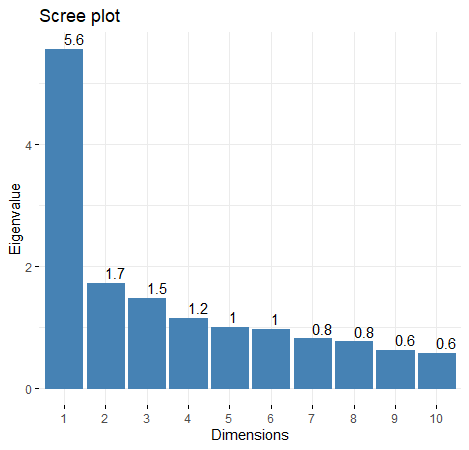
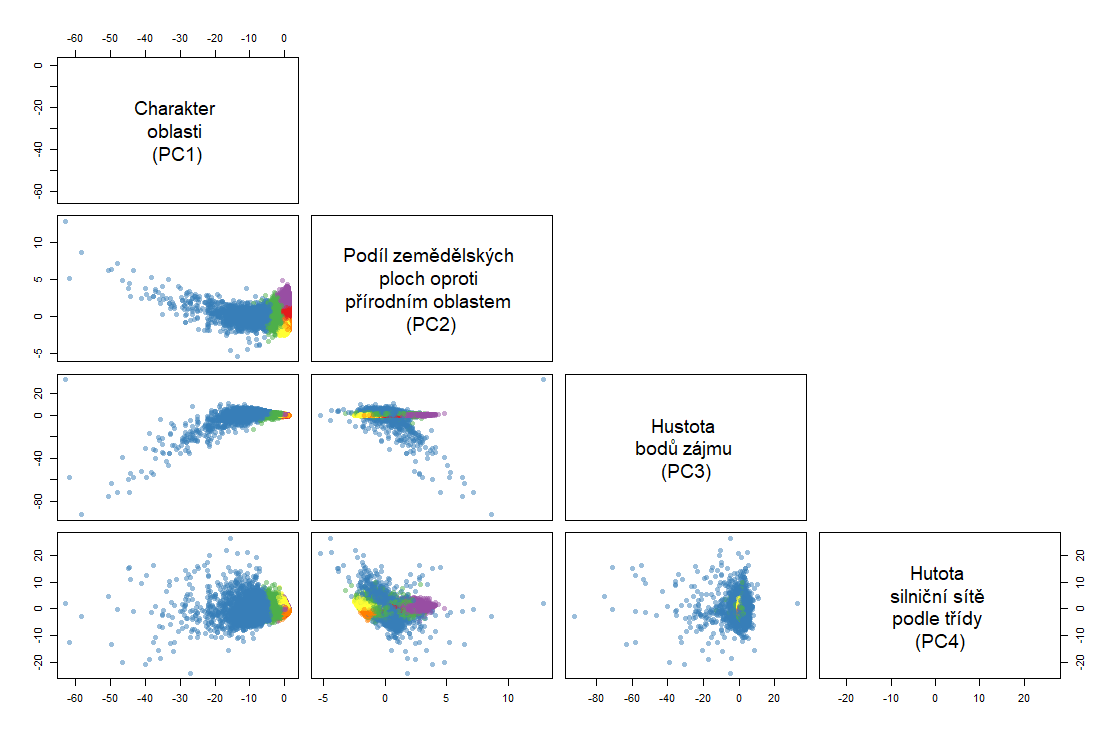
Pomocí indexového grafu úpatí vlastních čísel (Scree plot) byly vybrány „užitečné“ čtyři hlavní komponenty s hodnotou vlastních čísel vyšší než jedna. Graf komponentních vah (zátěží) pro první a druhou hlavní komponentu byl využit pro ohodnocení vlivu a důležitosti atributů na tyto komponenty a jejich vzájemného vztahu. Pomocí dvojného grafu byly vykresleny záznamy v prostoru prvních dvou hlavních komponent. Pomocí matice záteží a grafů znázorňujících příspěvky jednotlivých atributů do vybraných hlavích komponent byl interpretován význam hlavních komponent, což následně vedlo k jejich pojmenování.
1. hlavní komponenta – Charakter oblasti
2. hlavní komponenta – Podíl zemědělských ploch oproti přírodním oblastem
3. hlavní komponenta – Hustota bodů zájmu
4. hlavní komponenta – Hustota silniční sítě podle třídy
Hlavním výsledkem práce je typologie oblastí vytvořená shlukováním výsledku analýzy hlavních komponent. Pro shlukování byl použit algoritmus CLARA, rozšiřující algoritmus PAM. Důležitou částí shlukové analýzy bylo určení vhodného počtu shluků, k čemuž byly využity hodnoty siluet (tabulka 5). Vytvořeno bylo šest shluků, které byly interpretovány a pojmenovány (kapitola 8.1) pomocí vykreslení shluků v prostoru jednotlivých dvojic hlavních komponent, vizuální analýzy mapy zobrazující jednotky LAU2 zařazené do shluků a grafu zobrazující shluky podle počtu obyvatel a hustoty zalidnění.
Výrazně městské oblasti
Spíše městské oblasti
Venkovské oblasti s malým podílem zemědělských ploch
Venkovské oblasti s průměrným podílem zemědělských ploch
Venkovské oblasti s výrazným podílem zemědělských ploch a lepší silniční dostupností velkých měst
Venkovské oblasti s výrazným podílem zemědělských ploch a rozvinutou regionální silniční infrastrukturou
Shluky v prostoru hlavních komponent
Jednotlivé shluky byly popsány a charakterizovány. Uvedeny byly typické oblasti zařazené do těchto shluků včetně konkrétních příkladů a jejich vizualizací. Popsány byly i skutečnosti způsobující potenciálně špatné zařazení oblastí a některé oblasti jejichž zařazení je sporné. Celá výsledná vrstva byla zařazena do webové mapové aplikace, aby bylo umožněno její detailní prohlížení.
Agregací těchto shluků do prostorových jednotek NUTS2 bylo umožněno srovnání s daty Eurostatu. Vytvořeny byly tři nové atributy s informací o procentuálním zastoupení městských, venkovských a venkovských zemědělských oblastí v ploše NUTS2. Pro srovnání s nimi byla vytvořena vrstva NUTS2 s deseti atributy získanými z Eurostatu. Data byla srovnávána pomocí korelací. Korelace nebyly výrazně vysoké, pravděpodobně kvůli přílišné generalizaci informace, plynoucí z použití velkých prostorových jednotek NUTS2. Z tohoto srovnání se nedá s jistotou posuzovat správnost vytvořené klasifikace. Některé předpokládané vztahy, mezi podílem městských, venkovských a venkovských zemědělských byly potvrzeny, některé však byly nečekané a dokonce i opačné.
Poslední částí práce bylo vytvoření webové mapové aplikace, zobrazující výsledné vrstvy. Zahrnnuty do ní, mimo již zmíněné vrstvy shluků LAU2, byly také vrstvy procentuálního zastoupení městských, venkovských a venkovských zemědělských oblastí za jednotky NUTS2.
Závěr
Prvním cílem práce bylo obohatit datovou sadu jednotek LAU2 za území Evropské unie a přidružených států, které bylo vymezeno rozsahem původní vrstvy. Druhým cílem bylo provést nad těmito daty socioekonomické analýzy a především vytvořit typologii městských/venkovských oblastí v detailu jednotek LAU2 a pro celé území.
Pro obohacení datové sady byla využita data z otevřených zdrojů, konkrétně Open Street Map a CORINE Land Cover. Vytvořeno bylo třicet nových atributů. Na základě těchto nových atributů byla vytvořena typologie venkovských a městskýh oblastí, k čemuž byla použita analýza hlavních komponent. Použito bylo šestnáct atributů relevantních pro odlišení městských a venkovských oblastí. Vybrané čtyři užitečné hlavní komponenty byly analyzovány, interpretovány a pojmenovány. Samotná typologie byla vytvořena pomocí shlukové analýzy s použitím těchto čtyř hlavních komponent. Konkrétně byl použit nehirarchický shlukovací algoritmus CLARA. Pomocí statistiky tzv. siluet byl definován vhodný počet šesti shluků. Jednotlivé shluky, které představují typy oblastí (jednotek LAU2) byly pomocí grafů a vizuální analýzy mapy interpretovány a pojmenovány. Jednotlivé kategorie byly popsány, vymezeny byly typické oblasti zařazené do jednotlivých shluků včetně konkrétních příkladů. Uvedeny byly i některé problematické aspekty a potenciální chyby v této klasifikaci opět včetně konkrétních příkladů.
Následně byla vytvořená typologie jednotek LAU2 agregována do větších jednotek NUTS2, aby výsledek mohl být srovnán s dalšími daty Eurostatu. Kromě agregace do větších ploch, bylo původních šest shluků agregováno do třech typů oblastí NUTS2. Pro srovnání bylo použito korelací mezi deseti atributy z Eurostatu a třemi novými agregovanými atributy. Pro prezentaci výsledných vrstev byla vytvořena webová mapová aplikace.
Vytvořená typologie je jedinečná svým prostorovým rozsahem a detailem i použitými daty a definovanými typy oblastí, protože tematicky podobné typologie podobného prostorového rozsahu a detailu většinou využívají pouze počet obyvatel a hustotu zalidnění, větší množství atributů bývá využito většinou pouze pro menší území (jeden stát).
Summary
The diploma thesis deals with typology creation of rural and urban areas at the LAU2 spatial level in the European Union and its accociate countries. The theoretical part of the thesis is focused on the description of different methods of delimiting urban and rural areas. In the first phase of the work, an enriched dataset based on population size data in the regions of interest (provided by Eurostat) was created. Data, used for the enrichement, were obtained from open data sources. Simple urban/rural classifications are derived from the original data using only population size and population density attributes. The main part of the thesis is concerned with typology creation of rural and urban regions using Principal component analysis and Cluster analysis. The Important part lies in analysis and interpretation of the principal components and the resulting clusters, which represent individual types of urban and rural regions. Furthemore, the clusters are aggregated into NUTS2 spatial units and then compared to other Eurostat data, corresponding to the same spatial units. Finally, in order to present the main resulting layers, an online map application is presented.