
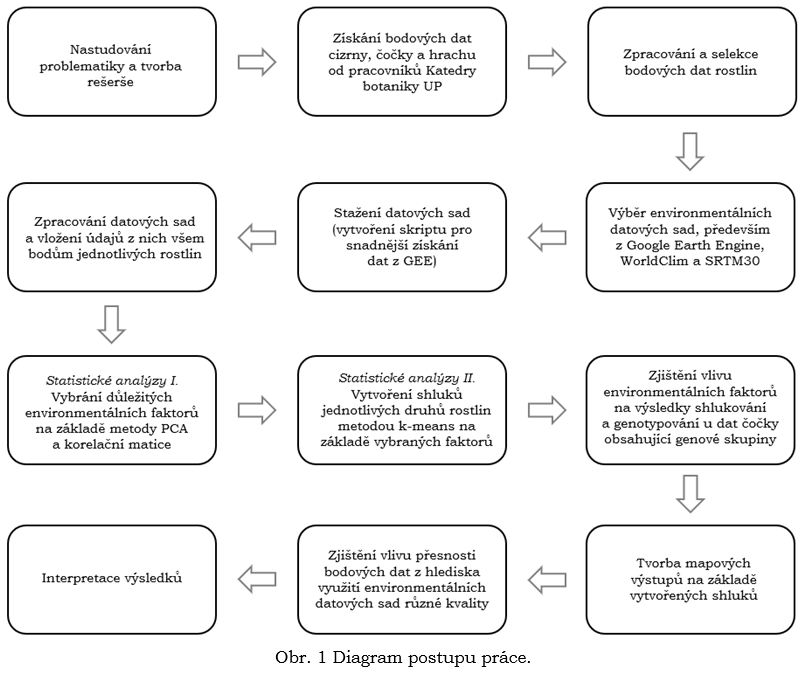
Postup práce koresponduje s vytyčenými cíli práce a je znázorněn na obr. 1. Nejprve byla sepsána rešerše, která je zaměřená na charakteristiku zkoumaných rostlin, popis klimatu
lokality výskytu těchto rostlin a dále na současný stav řešené problematiky. Dalším krokem bylo získání bodových dat cizrny, čočky a hrachu od pracovníků Katedry botaniky UP, která
byla následně zpracována a vytřízena. Třízení probíhalo na základě přesnosti dat, duplicity či nevhodného umístění bodů. Tento proces je blíže popsán v kapitole 5.1.
Dále byly na základě konzultace s odborníky vybrány environmentální datové sady, které by mohly napomoci při charakteristice výskytu rostlin. Jedná se především o data z platformy Google Earth
Engine, WorldClim a SRTM30. Vybrané datové sady byly následně staženy, u platformy Google Earth Engine musely být vytvořeny skripty, pomocí kterých lze data získat. Postup stahování dat je popsán
v kapitole 5.2 a vytvořené skripty se nachází v příloze 1 a 2. Následně bylo třeba environmentální datasety zpracovat a extrahovat jejich hodnoty všem bodům rostlin, aby bylo možné provádět další analýzy.
Jakmile byla data zpracována, bylo možné přistoupit ke statistickým analýzám, které byly prováděny v softwaru RStudio. První částí je výběr důležitých environmentálních faktorů, které mají
nejzásadnější vliv na výskyt zkoumaných rostlin. To bylo provedeno na základě analýzy hlavních komponent a korelační matice (viz kapitola 5.3.1). Na základě vybraných faktorů byly následně
vytvořeny shluky jednotlivých druhů rostlin, aby bylo možné popsat jejich závislost na těchto faktorech. Shlukování proběhlo pomocí metody k-means (viz kapitola 5.3.2). Součástí shlukové
analýzy je také porovnání výsledků shlukování u dat čočky obsahujících informaci o zařazení ke genetickým skupinám s výsledky genotypování.
Dalším krokem je vizualizace vytvořených shluků, a to pomocí grafu biplot a pomocí mapových výstupů. Poslední analýzou je zjištění vlivu přesnosti bodových dat z hlediska využití
environmentálních datových sad různé kvality. Zjištění vlivu přesnosti dat je popsáno v kapitole 5.3.3.
Posledním krokem, který je rozepsán v kapitole 6 je interpretace výsledků a výstupů.
© Přemysl Dratva 2020, Katedra geoinformatiky, Přírodověděcká fakulta Univerzity Palackého v Olomouci. | All rights reserved. | Design by TEMPLATED