Stanovení minimální absolutní chyby
Vlastní projekt
Ve druhé fázi byly na základě těchto bodů generovány nové povrchy. Bylo vybráno šest metod interpolace a každá měla pro konkrétní území vlastní nastavení parametrů (viz Tab. 2). To znamená, že nakonec nebyl testován vliv nastavení interních parametrů metod. Právě touto analýzou se totiž zabývala teprve v nedávné době dvojice Kadlčíková, Tuček (2008).
U metody IDW Nearest Neighbors byl použit fixní vyhledávací poloměr s tím, že jeho velikost byla nastavena tak, aby se v daném okruhu nevyskytl žádný jiný bod – a tím pádem dojde následně k naplnění minimálního počtu nejbližších sousedů. Variabilní poloměr má totiž fixní počet nejbližších sousedů a maximální vyhledávací poloměr.
U metody IDW Fixed Radius je vynucen minimální počet 4 nejbližších sousedů opět skrz fixní vyhledávací poloměr. Ten je nastaven tak, aby při dané hustotě bodů podchytil méně obsazená místa, takže ve většině případů je k interpolaci použito více než 4 bodů. U metod Spline (regularizovaný a s tenzí) byla nastavena doporučená hodnota váhy těsně pod horní hranicí typických hodnot (viz ArcGIS Desktop Help) a počet bodů na 8.
Tab. 2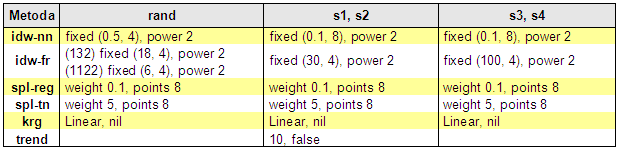
Kriging byl počítán pomocí příkazu MakeKriging. Kriging je náchylný na dostatečný počet bodů pro vykreslení povrchu. Nakonec byl proto zvolen lineární model s prahem a nebyl vyžadován specifický počet bodů, takže byla použita defaultní hodnota 12 bodů. Byl testován i gaussovský kriging, který ovšem často při nižších hustotách vstupních bodů na výstupu vracel vyloženě nereálné povrchy s velice extrémními hodnotami. U žádné z metod nebyly použity bariéry.
Trend byl proveden s polynomem 10. řádu. Pro vyšší řády u území s2 nebyl dostatek kontrolních bodů a povrch nebylo možné vykreslit. Interpolace trendem byla zařazena pouze pro území s1 a s2. Jak již bylo uvedeno, není to metoda pro interpolaci nadmořských výšek… u těchto dvou povrchů však dobře ilustruje své schopnosti.
Analýza metod se snažila zaměřit na náhodnost výběru bodů, pravidelnost a nepravidelnost v jejich rozmístění a také na hustotu bodů v ploše.
Pro každé území byly stanoveny podíly referenčních bodů (viz Tab. 1), které pak vstoupily do tvorby dílčích DMR. Byly vždy stanoveny dvě hustoty bodů, větší a menší, a bylo dbáno na to, aby v rámci dvojice území byla hustota bodů v ploše (podle počtu platných pixelů) stejná. Za zmínku stojí, že v případě rand, s3 i s4 bylo pro menší hustotu vybráno pouhé jedno procento referenčních bodů.
Za účelem snížení vysokého počtu referenčních bodů byl navíc pro území s3 (s4) uměle snížen počet bodů, ze kterých se vybíraly body pro interpolace, na čtvrtinu (zhruba šestinu).
Vliv pravidelného a nepravidelného rozmístění bodů byl testován na imaginárním území rand, které nativně obsahovalo 100×100 pravidelně rozložených známých hodnot. Počty vybíraných bodů byly řízeny pravidelnou strukturou 3×3 a 9×9 bodů. Při ideálním výběru 3×3 (tj. 1., 4., 7. až 100. bod v řádku a každý 1., 4. až 100. řádek) dostaneme 34×34=1156 bodů. V úvahu však byly brány i kombinace s posunutým řádkem či sloupcem (ne zároveň), a tak docházíme k číslu 33×34=1122 a celkem pěti kombinacím pro výběr bodů. Pro výběr 9×9 obdobně: ideální výběr 12×12=144 bodů, posunutý řádek či sloupec 11×12=132 a celkem 17 kombinací.
Náhodnost byla zakomponována opakovaným náhodným výběrem zvoleného počtu bodů z referenční sady. Jako relevantní byla určena hodnota 100 opakování. Ta byla aplikována na území s1, s2 a rand pro nepravidelný výběr (pro pravidelný výběr bylo dáno 5, resp. 17 kombinací výběrů). Území s3 a s4 prošlo pouze 25 opakováními (viz dále).
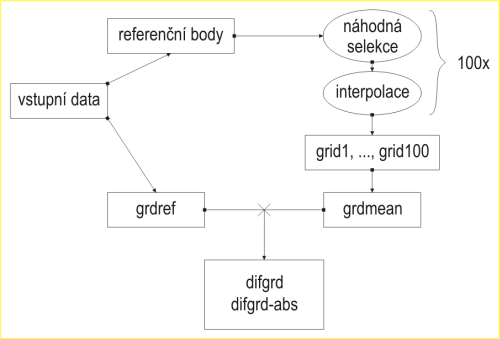
Postup práce dokumentuje Obr. 1. Z referenční sady bodů bylo 100krát vybráno určité kvantum bodů, jež pak byly použity pro interpolaci 100 povrchů zvolenou metodou viz Tab. 2. Aritmetickým průměrem pak byl odvozen průměrový povrch grdmean, který byl následně odečten od referenčního grdref za vzniku rozdílového (diferenčního) gridu difgrd. Absolutní odchylku potom vyjadřuje grid s názvem difgrd-abs.
 Obr. 1
Obr. 1
Pokud uvážíme, z kolika bodů byl zvolený počet bodů stokrát vybírán, teoreticky nemohlo dojít k situaci, že by v rámci jednoho běhu byla vybrána stejná sada bodů. Naopak, pro objektivnost mohl být počet opakování i vyšší (např. 1000). Největší procento bodů bylo vybíráno na území s1, a to 69 % (340 ze 491).
Proces náhodné selekce bodů a jejich interpolace byl řízen autorským skriptem viz Příloha 10. Všechny použité skripty jsou k nalezení na DVD ve složce /projekt/skripty/. Je zde i skript generující průměrový grdmean a skript pro pravidelný výběr nad územím rand. Skripty jsou v základní podobě – pro konkrétní použití je nutné aktualizovat vybrané proměnné.
Hlavní výběrový skript nejdříve načte referenční grid, ze kterého si přečte Analysis Properties (extent, cell size, mask). Poté je načtena sada referenčních bodů, je definován počet opakování a počet vybíraných bodů. Pak přichází vlastní procedura výběru na základě jednoznačného identifikátoru bodu v atributové tabulce. Funkcí je vybráno náhodné číslo od 1 do celkového počtu záznamů. Příkaz Query najde bod o shodném ID. Vybraný bod je přidán do tzv. bitmapy, která má rozsah rovný počtu referenčních bodů a hodnoty True nebo False pro vybraný či nevybraný bod. Po dosažení kritické hodnoty je nad vybranými body spuštěna interpolace a vygenerován dílčí grid. Zároveň je do textového souboru zapsána jeho statistika (min, max, mean, standard deviation).
Hardwarová náročnost procedury výběru a interpolace je výrazně ovlivněna počtem záznamů v atributové tabulce referenčních bodů, počtem vybíraných bodů, velikostí interpolovaného území, použitou metodou interpolace (IDW vs. Spline) i nastavením jejích parametrů (např. výběr 4 nebo 8 nejbližších sousedů) a samozřejmě i počtem opakování úkonu. Např. vygenerování 100 gridů nad nepravidelně rozmístěnými 1122 body na území rand trvalo před 4 hodiny. Proto bylo přistoupeno ke snížení počtu referenčních bodů a pouze k 25 opakováním u území s3 a s4. Zejména počet opakování tak degraduje účinnost náhodnosti.